HASHING: GUIDE FOR BEGINNERS
Hashing is one of those important topics that the interviewer will ask you in every interview because organizing and searching for data are such widespread problems in computing, hashing algorithms have become crucial to cryptography (If Cryptography was a body, its Hashing Algorithm would be the heart of it. If Cryptography was the Solar System, its Hashing Algorithm would be the Sun. If Cryptography was a car, its Hashing Algorithm would be its engine. If Cryptography was a movie, its Hashing Algorithm would be the protagonist, Okay, that’s too far but you’ve got the point, right?), graphics, telecommunications. For example, every time you send a credit card number over the Web or use your word processor's dictionary, hash functions are at work.
Before we get to the what hashing algorithm is, why it’s there, and how it works; it’s important to understand where its nuts and bolts are. Let’s start with Hashing.
Hashing provides constant time search, insert and delete operations on average. This is why hashing is one of the most used data structure, example problems are, distinct elements, counting frequencies of items, finding duplicates, etc. And also with the help of hashing, you can perform the insertion, deletion, and searching operation in O (1) time. Yes, you heard it right. So, in this blog, you will learn about how the idea of Hashing works in Programming.
So, let's get started with some basics of Hashing.
Basics of Hashing…
As the name loosely suggests, hashing is a process for chopping up and mixing information. In a typical data operation, a string of characters will be transformed into a shorter string of fixed length which represents the original character string. This reduced-length value is also known as a key.

How hashing works???
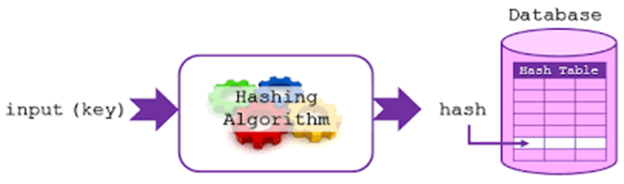
In hash tables, you store data in forms of key and value pairs. The key, which is used to identify the data, is given as an input to the hashing function. The hash code, which is an integer, is then mapped to the fixed size we have.
Hash tables have to support 3 functions.
insert (key, value)
get (key)
delete (key)
Purely as an example to help us grasp the concept, let us suppose that we want to map a list of string keys to string values (for example, map a list of countries to their capital cities). So, let’s say we want to store the data in Table in the map. And let us suppose that our hash function is to simply take the length of the string.
For example, Cuba has a hash code (length) of 4. So, we store Cuba in the 4th position in the keys array, and Havana in the 4th index of the values array etc. And we end up with the following:

Hashing Function: The Core of Hashing Algorithm
“Behind every successful man, there is a great woman.” — Groucho Marx
“Behind every successful hash algorithm, there is a great hash function.” – We just made that up.
Let’s put the jokes aside for a moment and concentrate on the crux of the matter. A hash function is a mathematical function that converts an input value into a compressed numerical value – a hash or hash value. Basically, it’s a processing unit that takes in data of arbitrary length and gives you the output of a fixed length – the hash value.
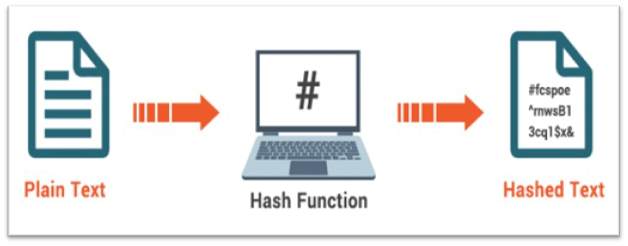
Hash Function:
Hash functions or hashing algorithms are the mathematical procedures used in computing hash values from base input numbers and character strings. They may be highly complex, and can produce a hash value that’s almost impossible to derive from the original input data without knowing the applied hash function. For this reason, the keys used in public key encryption may be derived from such algorithms.
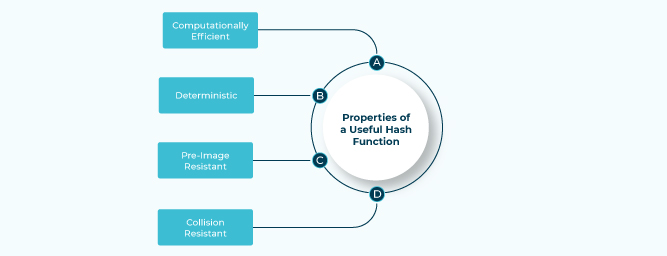
A good hash function should have following properties -
1) Efficiently computable.
2) Should uniformly distribute the keys (Each table position equally likely for each key)
What are the Properties of a Useful Hash Function?
Hash Table:
An array that stores pointer to records corresponding to a given phone number. An entry in the hash table is NIL if no existing phone number has hash function value equal to the index for the entry.

Some important notes about hash tables:
Values are not stored in a sorted order.
You must account for potential collisions. This is usually done with a technique called chaining. Chaining means to create a linked list of values, the keys of which map to a certain index.
Now let’s move on to the part you’ve been waiting for.
Popular Hashing Algorithms
Here are some relatively simple hash functions/algorithms that have been used:
1)Collision Handling:
Since a hash function gets us a small number for a big key, there is possibility that two keys result in same value. The situation where a newly inserted key maps to an already occupied slot in hash table is called collision and must be handled using some collision handling technique.
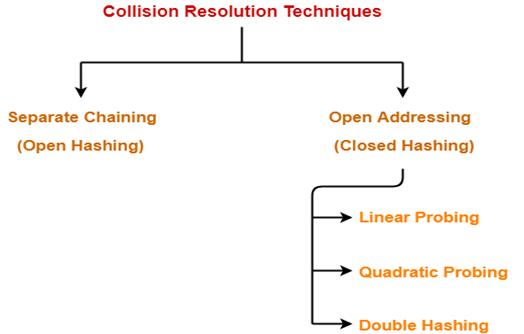
Whenever a collision occurs in a hash table, then that collision can be resolved using two techniques:
1. Chaining - The idea is to make each cell of hash table point to a linked list of records that have same hash function value. Chaining is simple, but requires additional memory outside the table.
2. Open Addressing - In open addressing, all elements are stored in the hash table itself. Each table entry contains either a record or NIL. When searching for an element, we one by one examine table slots until the desired element is found or it is clear that the element is not in the table.
2)The Division-remainder Method:
This is a relatively basic hashing algorithm in which the total number of items in a data array is estimated. This figure is then divided into each data string value to give a quotient (which is disregarded) and a remainder – which is taken as the hash value. Clearly, with a large number of figures, many duplicate remainders emerge, leading to the possibility of multiple collisions. So search algorithms for such data sets must take this flaw into account.
3) Folding Function:
It involves the procedure of splitting keys into two or more parts and then combining the pieces and form the hash addresses.Example- To map the key 26456715 to a range between 0 and 9999, you can: split the number into two as 2645 and 6715, and then add these two to obtain 9360 as the hash value.
4)The Radix Transformation Method:
Radix function transforms a key into another number base, and you thus obtain the hash value. It typically uses number base other than base 10 and base 2 to calculate the hash addresses.
5)The Digit Rearrangement Method:
This method uses a simple substitution in which a pre-determined part of the original data string is reversed, and taken as the hash value for the string.
6)Secure Hash Algorithm-2 (SHA-2):
SHA-2, developed by the National Security Agency (NSA), is a cryptographic hash function. SHA-2 includes significant changes from its predecessor, SHA-1. The SHA-2 family consists of six hash functions with digests (hash values) that are 224, 256, 384 or 512 bits: SHA-224, SHA-256, SHA-384, SHA-512, SHA-512/224, SHA-512/256.
7)MD5:
An MD5 hash function encodes a string of information and encodes it into a 128-bit fingerprint. MD5 is often used as a checksum to verify data integrity. However, due to its age, MD5 is also known to suffer from extensive hash collision vulnerabilities, but it’s still one of the most widely used algorithms in the world.
8)CRC32:
A cyclic redundancy check (CRC) is an error-detecting code often used for the detection of accidental changes to data. Encoding the same data string using CRC32 will always result in the same hash output, thus CRC32 is sometimes used as a hash algorithm for file integrity checks. These days, CRC32 is rarely used outside of Zip files.
There are several well-known hash functions used in cryptography. These include the message-digest hash functions MD2, MD4, used for hashing digital signatures into a shorter value called a message-digest, and the Secure Hash Algorithm (SHA), a standard algorithm, that makes a larger (60-bit) message digest and is similar to MD4. A hash function that works well for database storage and retrieval, however, might not work as for cryptographic or error-checking purposes.
Shall We Wrap Up?
In conclusion, hash is a useful tool which verifies that the data is copied correctly between two resources. It can also check if the data are identical without opening and comparing them. We can use it primarily for retrieval of items in a database as it makes it quicker to find the item using a short hash key than to locate it using the original value.
It ensures that the messages during transmission are not tamper with and thus plays a vital role in the data security system. It is also uses for encrypting and decrypting digital signatures using hash codes.
Happy Learning, Enjoy Algorithms!!!

👍👍
ReplyDeleteExcellent🤩
ReplyDeleteGood content!!
ReplyDeleteComprehensive write-up 🙌
ReplyDeleteGreat content👍
ReplyDeleteInformative✌🏻
ReplyDeleteGood content..🙌
ReplyDeleteWell explained 👍🏻
ReplyDeleteAwesome👏
ReplyDeleteNice presentation, nice blog 👍
ReplyDeleteGreat work, very informative !!
ReplyDeleteGreat information✌
ReplyDeleteVery imformative and useful 👍
ReplyDeleteGreat Content
ReplyDeleteGood content ..it really helps for understanding.
ReplyDeleteGood one👍👍
ReplyDeleteGreat! Quiet informative
ReplyDeleteAwesome👍
ReplyDeleteThis comment has been removed by the author.
ReplyDeleteInformative blog 🙌
ReplyDeleteGood and informative blog
ReplyDeleteHelpful blog 😄👍
ReplyDeleteGreat share !informative one ��
ReplyDeleteGreat work!!
ReplyDelete